
For the Black Ops Testing Webinar on 22nd September 2014 we were testing Taskwarrior, a CLI application.
I test a lot of Web software, hence the “Technical Web Testing 101” course, but this was a CLI application so I needed to get my Unix skills up to date again, and figure out what supporting infrastructure I needed.
By the way, you can see the full list of notes I made at github. In this post I’m going to explain the thought process a little more.
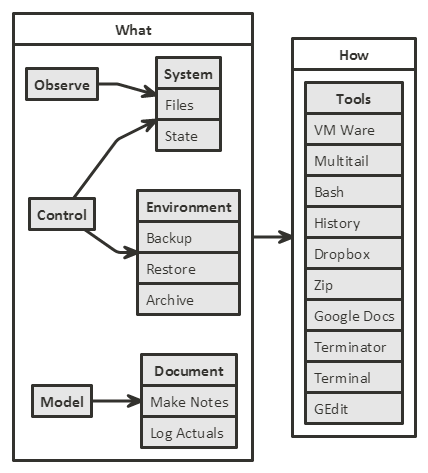
Before I started testing I wanted to make sure I could meet my ’technical testing’ needs:
- Observe the System
- Control the Environment
- Restore the App to known states
- Take time stamp logs of my testing
- Backup my data and logs from the VM to my main machine
And now I’ll explain how I met those needs… and the principles the process served.
You will also find here a real life exploratory testing log that I wrote as I tested.
Observe the System
Part of my Technical Testing approach requires me to have the ability to Observe the system that I test.
With the web this is easy, I use proxies and developer tools.
How to do this with a CLI app? Well in this case Taskwarrior is file based. So I hunted around for some file monitoring tools.
I already knew about Multitail, so that was my default. ‘Tail’ allows you to monitor the changes to the end of a file. Multitail allows me to ’tail’ multiple files in the same window.
I looked around for other file monitoring tools, but couldn’t really find any.
With Multitail I was able to start it with a single command that was ‘monitor all files in this directory’
multitail -Q 1 ~/.task/*
I knew that the files would grow larger than tail could display, so I really wanted a way to view the files.
James Lyndsay used Textmate to see the files changing. I didn’t have time to look around for an editor that would do that (and I didn’t know James was using Textmate because we test in isolation and debrief later so we can all learn from each other and ask questions).
So I used gedit. The out of the box editing tool on Linux Ubuntu. This will reload the file if it has changed on the disk when I change tabs. And since I was monitoring the files using Multitail, I knew when to change tabs.
OK, so I’m ‘good’ on the monitoring front.
Control the Environment
Next thing I want the ability to do? Reset my environment to a clean state.
With Taskwarrior that simply involves deleting the data files:
rm ~/.task/*
Restore the App to known states
OK. So now I want the ability to backup my data, and restore it.
I found a backup link on the Taskwarrior site. But I wanted to zip up the files rather than tar them, simply because it made it easier to work cross platform.
zip -r ~/Dropbox/shared/taskData.zip ~/.task
The above zips up, recursively, a directory. I used recursive add, just in case Taskwarrior changed its file setup as I tested. Because my analysis of how it stored the data was based on an initial ‘add a few tasks’ usage I could not count on it remaining true for the life of the application usage. Perhaps as I do more complicated tasks it would change? I didn’t know, so using a ‘recursive add’ gave me a safety net.
Same as the Multitail command, which will automatically add any new files it finds in the directory, so it added a history file after I started monitoring.
Backup my data and logs from the VM to my main machine
I would do most of my testing in a VM, and I really wanted the files to exist on my main machine because I have all the tools I need to edit and process them there. And rather than messing about with a version control system or shared folders between VM etc.
I decided the fastest way of connecting my machines was by using Dropbox. So I backup the data and my logs to Dropbox on the VM and it automatically syncs to all my other machines, including my desktop.
Take time stamp logs of my testing
I had in the back of my mind that I could probably use the history function in Bash to help me track my testing.
Every command you type into the Bash shell is recorded in the history log. And you can see the commands you type if you use the ‘history command. You can even repeat them if you use ‘!’ i.e. ‘!12’ repeats the 12th command in the history.
I wanted to use the log as my ’these are the actual commands I typed in over this period of time.
So I had to figure out how to add time stamps to the history log
export HISTTIMEFORMAT='%F %T
I looked for simple way to extract items from the history log to a text file, but couldn’t find anything in time so I eventually settled on a simple redirect e.g. redirect the output from the history command to a text file (in dropbox of course to automatically sync it)
history > ~/Dropbox/shared/task20140922_1125_installAndStartMultiTail.txt
And since I did not add the HISTTIMEFORMAT to anything global I tagged it on the front of my history command
export HISTTIMEFORMAT='%F %T '; history > ~/Dropbox/shared/task20140922_1125_installAndStartMultiTail.txt
I added ‘comments’ to the history using the ‘echo’ command, which displays the text on screen and appears in the history as an obviously non-testing command.
I also found with history:
- add a ’ ’ space before the command and it doesn’t appear in the history - great for ’non core’ actions
- you can delete ‘oops’ actions from the history with ‘history -d #number’
And that was my basic test environment setup. If I tracked this as session based testing then this would have been a test environment setup session.
All my notes are in the full testing notes I made.
I could have gone further:
- ideally I wanted to automatically log the output of commands as well as the command input
- I could have figured out how to make the HISTTIMEFORMAT stick
- I could have figured out how to have the dropbox daemon run automatically rather than running in a command window
- I could have found a tool to automatically refresh a view of the full file (i.e. as James did with textmate)
- etc.
But I had done enough to meet my basic needs for Observation, Manipulation and Reporting.
Oh, and I decided on a Google doc for my test notes very early on, because, again, that would be real time accessible from all the machines I was working from. I exported a pdf of the docs to the gihub repo.
And what about the testing?
Yeah, I did some testing as well. You can see the notes I made for the testing in the github repo.
So how did the tools help?
As I was testing, I was able to observe the system as I entered commands.
So I ’task add’ a new task and I could see an entry added to the pending.data, and the history.data, and the undo.data.
As I explored, I was able to see ‘strange’ data in the undo.data file that I would have missed had I not had visibility into the system.
You are able to view the data if you want, because I backed up up as I went along, and it automatically saved to dropbox, which I later committed to github.
What else?
At the end of the day, I spent a little time on the additional tooling tasks I had noted earlier.
I looked at the ‘script’ command which allows you to record your input and output to a file, but since it had all the display esc characters in it, it wasn’t particularly useful for reviewing.
Then I thought I’d see what alternative terminal tools might be useful.
I initially thought of Terminator, since I’ve used it before. And when I tried it, I noticed the logger plug-in, which would have been perfect, had I had that at the start of my testing since the output is human readable and captures the command input and the system output as you test. You can see an example of the output in the github repo.
I would want to change the bash prompt so that it had the date time in it though so the log was more self documenting.
You can see the change in my environment in the two screenshots I captured.
- The initial setup was just a bunch of terminals
- The final setup has Terminator for the execution, with gedit for viewing the changed files, and multitail on the right showing me the changes in the system after each command
Principles
And as I look over the preceding information I can pull out some principles that underpin what I do.
- Good enough tooling
- Ideally I’d love a fully featured environment and great tools, but so long as my basic needs are met, I can spend time on testing. There is no point building a great environment and not testing. But similarly, if I don’ t have the tools, I can’t see and do certain things that I need in my testing.
- Learn to use the default built in tools
- Gedit, Bash, History - none of that was new. By using the defaults I have knowledge I can transfer between environments. And can try and use the tools in more creative ways e.g. ’echo’ statements in the history
- Automated Logging doesn’t trump note-taking
- Even if I had Terminator at the start of my testing, and a full log. I’d still take notes in my exploratory log. I need to write down my questions, conclusions, thoughts, research links, etc. etc.
- If I only had one, I’d take my exploratory log above any automated log taking tool.
- Write the log to be read
- When you read the exploratory log, I think it is fairly readable (you might disagree). But I did not go back and edit the content. That is all first draft writing.
- What do I add in the edit? I answer any questions that I spot that I asked and answered. I change TODOs that I did. etc. I try not to change the substance of the text, even if my ‘conclusions’ as to how something are working are wrong at the start, but change at the end, I leave it as is, so I have a log of my changing model.
- When you read the exploratory log, I think it is fairly readable (you might disagree). But I did not go back and edit the content. That is all first draft writing.
You might identify other principles in this text. If you do, please leave a comment and let me know.
Why didn’t you use tool X?
If you have particular tools that you prefer to use when testing CLI applications then please leave a comment so I can learn from your experience.






