
or “Why I explored Taskwarrior the way I did”.
In a previous post I discussed the tooling environment that I wanted to support my testing of Taskwarrior for the Black Ops Testing webinar of 22nd September 2014.
In this post, I’ll discuss the ‘actual testing’ that I performed, and why I think I performed it the way I did. At the end of the post I have summarised some ‘principles’ that I have drawn from my notes.
I didn’t intend to write such a long post, but I’ve added sections to break it up. Best of luck if you make it all the way through.
First Some Context
First, some context:
- 4 of us, are involved in the testing for the webinar
- I want the webinars to have entertainment and educational value
- I work fast to try and find ’talking points’ to support the webinar The above means that I don’t always approach the activity the same way I would a commercial project, but I use the same skills and thought processes.
Therefore to meet the context:
- I test to ‘find bugs fast’ because they are ’talking points’ in the webinar
- I explore different ways of testing because we learn from that and can hopefully talk about things that are ’new’ for us, and possibly also new for some people on the webinar
I make these points so that you don’t view the testing in the webinar as ’this is how you should do exploratory testing’ but you understand ‘why’ I perform the specific exploration I talk about in the webinar.
And then I started Learning
So what did I do, and what led to what?
(At this point I’m reading my notes from github to refresh my memory of the testing)
After making sure I had a good enough toolset to support my testing…
I spent a quick 20 minutes learning the basics of the application using the 30 second guide.
At this point I knew ‘all you need to know’ to use the application and create tasks, delete tasks, complete tasks and view upcoming tasks.
Because of the tooling I set up, I can now see that there are 4 files used in the application to store data (in version 2.2)
- pending.data
- history
- undo.data
- completed.data
From seeing the files using multitail, I know:
- the format of the data
- items move from one file to another
- undo.data has a ‘before’ and ‘after’ state
- history would normally look ’empty’ when viewing the file, but because I’m tailing it, I can see data added and then removed, so it acts as a temporary buffer for data
In the back of my head now, I have a model that:
- there might be risks moving data from one file to another if a file was locked etc.
- text files can be amended,
- does the app handle malformed files? truncated files? erroneous input in files?
- state is represented in the files, so if the app crashed midway then the files might be out of sync
- undo would act on a task action by task action
- as a user, the text files make it simpler for me to recover from any application errors and increase the flexibility open to me as a technical user
- as a tester, I could create test data pretty easily by creating files from scratch or amending the files
- as a tester, I can put the application into the state I want by amending the files and bypassing the GUI
All of these things I might want to test for if I was doing a commercial exploratory session - I don’t pursue these in this session because ‘yes they might make good viewing’ but ‘I suspect there are bugs waiting in the simpler functions’.
After 20 minutes:
- I have a basic understanding of the application,
- I’ve read minimal documentation,
- I’ve had hands on experience with the application,
- I have a working model of the application storage mechanism
- I have a model of some risks to pursue
I take my initial learning and build a ‘plan’
I decide to experiment with minimal data for the ‘all you need to know’ functionality and ask myself a series of questions, which I wrote down as a ‘plan’ in my notes.
- What if I do the minimal commands incorrectly?
Which I then expanded as a set of sub questions to explore this question:
- if I give a wrong command?
- if I miss out an id?
- if I repeat a command?
- if a task id does not exist?
- if I use a priority that does not exist?
- if I use an attribute that does not exist?
This is not a complete scope expansion for the command and attributes I’ve learned about, but this is a set of questions that I can ask of the application as ’tests’.
I gain more information about the application and learn stuff, and cover some command and data scope as I do so.
I start to follow the plan
10 minutes later I start ’testing’ by asking these questions to the application.
Almost immediately my ‘plan’ of ‘work through the questions and learn stuff’ goes awry.
I chose ‘app’ as a ‘wrong command’ instead of ‘add’. but the application prompts me that it will modify all tasks. I didn’t expect that. So I have to think:
- the message by the application suggests that ‘app’ == ‘append’
- I didn’t know there was an append command, I didn’t spot that. A quick ’task help | grep append’ tells me that there is an append command. I try to grep for ‘app’ but I don’t see that ‘app’ is a synonym for append. Perhaps commands can be truncated? (A question about truncation to investigate for later)
- I also didn’t expect to see 3 tasks listed as being appended to, since I only have one pending task, one completed task, and one deleted task. (Is that normal? A question to investigate in the future)
And so, with one test I have a whole new set of areas to investigate and research. Some of this would lead to tests. Some of this would lead to reading documentation. Some of this would lead to conversations with developers and analysts and etc. if I was working on a project.
I conduct some more testing using the questions, and add the answers to my notes.
I also learn about the ‘modify’ command.
Now I have CRUD commands: ‘add’, ’task’, ‘modify’ | ‘done’, ‘delete’
I can see that I stop my learning session at that point - it coincidentally happens to be 90 mins. Not by design. Just, that seemed to be the right amount of time for a focused test learning session.
I break and reflect
When I come back from my break, I reflect on what I’ve done and decide on an approach to ask questions of:
- how can I have the system ‘show’ me the data? i.e. deleted data
- how can I add a task with a ‘due’ date to explore more functionality?
These questions lead me to read the documentation a little more. And I discover how to show the internal data from the system using the ‘info’ command. I also learn how to see ‘deleted’ tasks and a little more about filtering.
Seeing the data returned by ‘info’ makes me wonder if I can ‘modify’ the data shown there.
I start testing modify
I already know that I can delete a task with the delete command. But perhaps I can modify the ‘status’ and create a ‘deleted’ task that way?
And I start to explore the modify command using the attributes that are shown to me, by the application. (you can see more detail in the report)
And I can ‘delete’ a task using the modify, but it does not exercise the full workflow i.e. the task is still in the pending file until I issue a ‘report’.
My model of the application changes:
- reporting - actually does a data clean up, prior to the report and moves deleted tasks and hanging actions so that the pending file is ‘clean’
- ‘modify’ bypasses some of the top level application controls so might be a way of stressing the functionality a little
At this point, I start to observe unexpected side-effects in the files. And I find a bug where I can create a blank undo record that I can’t undo (we demonstrate this in the webinar).
This is my first ‘bug’ and it is a direct result of observing a level lower than the GUI, i.e. at a technical level.
I start modifying calculated fields
I know, from viewing the storage mechanism that some fields shown on the GUI i.e. ID, and Urgency. Do not actually exist. They do not exist in the storage mechanism in the file. They are calculated fields and exist in the internal model of the data, not in the persistent model.
So I wonder if I can modify those?
The system allows me to modify them, and add them to the persistence mechanism, but ignores them for the internal model.
This doesn’t seem like a major bug, but I believe it to be a bug since other attributes I try to modify, which do not exist in the internal model e.g. ’newAttrib’ and ‘bob’ are not accepted by the modify command, but ‘id’ and ‘urgency’ are.
I start exploring the ’entry’ value
The ’entry’ value is the date the task was entered. This is automatically added:
- Should I be able to amend it?
- What happens if I can?
So I start to experiment.
I discover that I can amend it, and that I can amend it to be in the future.
I might expect this with a ‘due’ date. But not a ’task creation date’ i.e. I know about this task but it hasn’t been created yet.
I then check if this actually matters. i.e. if tasks that didn’t officially exist yet are always less urgent than tasks that do, then it probably didn’t matter.
But I was able to see that a task that didn’t exist yet was more urgent than a task that did.
Follow on questions that I didn’t pursue would then relate to other attributes on the task:
- if the task doesn’t exist yet, should priority matter?
- Can I have a due date before the entry exists?
- etc.
Since I was following a defect seam, I didn’t think about this at the time.
And that’s why we review our testing. As I’m doing now. To reflect on what I did, and identify new ways of using the information that I found.
Playtime
I’d been testing for a while, so I wanted a ’lighter’ approach.
I decided to see if I could create a recurring task, that recurred so quickly, that it would generate lots of data for me.
Recurring tasks are typically, weekly or daily. But what if a task repeated every second? in a minute I could create 60 and have more data to play with.
But I created a Sorcerers Apprentice moment. Tasks were spawning every second, but I didn’t know how to stop them. The application would not allow me to mark a ‘parent’ recurring task as done, or delete a ‘parent’ recurring task. I would have to delete all the children, but they were spawning every second. What could I do?
I could probably amend the text files, but I might introduce a referential integrity or data error. I really wanted to use the system to ‘fix’ this.
Eventually I turned to the ‘modify’ command. If I can’t mark the task as ‘deleted’ using the ‘delete’ command. Perhaps I can bypass the controls and modify it to ‘status:deleted’
And I did. So a ‘bug’ that I identify about bypassing controls, was actually useful for my testing. Perhaps the ‘modify’ command is working as expected and is actually for admins etc.
Immediate Reflection
I decided to finish my day by looking at my logs.
I decided:
- If only there were a better way of tracking the testing.
Which was one of the questions I identify in my ’tool setup session’ but decided I had a ‘good enough’ approach to start.
And now, having added some value with testing, and learning even more about what I need the tooling to support. I thought I could justify some time to improve my tooling.
I had a quick search, experimented with the ‘script’ command, but eventually found that using a different terminal which logged input and output would give me an eve better ‘good enough’ environment.
Release
We held the Black Ops Testing Webinar and discussed our testing, where I learned some approaches from the rest of the team.
I released my test notes to the wild on github.
Later Reflection
This blog post represents my more detailed reflection on what I did.
This reflection was not for the purpose of scope expansion, clearly I could do ‘more’ testing around the areas I mentioned in my notes.
This reflection was for the purpose of thinking through my thinking, and trying to communicate it to others as well as myself. Because it is all very well seeing what I did, with the notes. And seeing the questions that I wrote allows you to build a model of my test thinking. But a meta reflection on my notes seemed like a useful activity to pursue.
If you notice any principles of approaches in my notes that I didn’t document here, then please let me know in the comments.
Principles
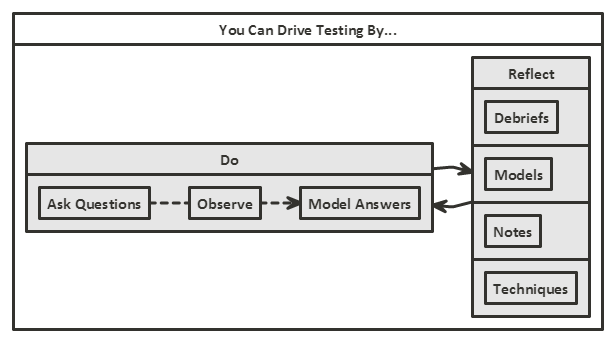
- Questions can drive testing…
- You don’t need the answers, you just need to know how to convert the question into a form the application can understand. The application knows all the answers, and the answers it gives you are always correct. You have to decide if those ‘correct’ answers were the ones you, or the spec, or the user, or the data, or etc. etc., actually wanted.
- The answers you receive from your questions will drive your testing
- Answers lead to more questions. More questions drive more testing.
- The observations you make as you ask questions and review your answers, will drive your testing.
- The level to which you can observe, will determine how far you can take this. If you only observe at the GUI layer then you are limited to a surface examination. I was able to observe at the storage layer, so I was able to pursue different approaches than someone working at the GUI.
- Experiment with internal consistency
- Entity level with consistency between attributes
- Referential consistency between entities
- Consistency between internal storage and persistent storage
- etc.
- Debriefs are important to create new plans of attack
- personal debriefs allow you to learn from yourself, identify gaps and new approaches
- your notes have to support your debriefs otherwise you will work from memory and don’t give yourself all the tools you need to do a proper debrief.
- Switch between ‘serious’ testing and ‘playful’ testing
- It gives your brain a rest
- It keeps you energised
- You’ll find different things.






